School/Compiler¶







-Week 2 03-05-lexical-specifications
使用 正则表达式 来声明不同的编程语言
正则表达式的一些使用例子
1. 关键字
例如对于这三个关键字:if、else、then:
| Text Only | |
|---|---|
也可以写作:
| Text Only | |
|---|---|
2. 整型
整型:由数位组成的非空字符串
| Text Only | |
|---|---|
于是可以写作 $$ digit^+ $$
3. 标识符
标识符:由字母或数字组成的,以字母开头的非空字符串
| Text Only | |
|---|---|
这可以写作
| Text Only | |
|---|---|
于是可以写作 $$ letter(letter + digit)^* $$
4. 空白
空白:由空格、换行、制表符组成的的非空字符串
| Text Only | |
|---|---|
5. Pascal

-Week 2 03-02-lexical-analysis-examples
一些词法分析的例子
Fortran
对于 FORTRAN 语言来说,有一个性质/规则:空白是没有影响的。
比如 VAR1 与 VA R1 是等价的,也就是说,一个 FORTRAN 程序可以不包含任何空白。
看下面这个例子:
第一行为循环,其中 DO 为循环关键字,5 为循环的标签,I 为循环迭代变量,范围为 1 到 25。
第二行为变量赋值,其中 DO 5 I 整体是一个变量名,也就是 DO5I = 1.25。
当我们对这两行分别做词法分析时,从左到右扫描字符串,到 DO 后面时,是无法确定这个 DO 是循环的关键字还是变量名的一部分,这时候我们需要更多的信息,直到后面的 , 与 . 的区别才能够得出结果,这被称作是 look ahead。
你也会注意到如果存在过多的 look ahead 会对词法分析系统的实现变得复杂,因此词法系统的设计目标之一就是最小化 lookahead 的数量。
Fortran 如此设计的原因是早期在穿孔卡片机上编写程序时很容易多出一些空格
对字符串进行分割,从左到右扫描,一次识别一个 token。
PL/1
对于 PL/1 语言来说,有一个性质:关键字并不是保留的。
也就是说,一个关键字也有可能是用户定义的变量名:
```pl/1 IF ELSE THEN THEN = ELSE; ELSE ELSE = THEN
难以区分 DECLARE 是关键字还是一个数组引用。
需要一路扫描经过整个 N 个 ARG,来得到后面是否为 = 来判断,这被称作 unbounded lookahead。
C++
在 C++ 中的流运算符和嵌套模板:
| C++ | |
|---|---|
| C++ | |
|---|---|
在老的编译器中对于嵌套模板的右侧的两个 > 需要写作 > >,不过目前大多数编译器都支持识别了。
-Week 2 03-03-regular-languages-part-1
之前讲到 词法单元的类型(Token Class)就是若干字符串组成的集合。
常用 正则语言(Regular Language)来表达这些集合。
两个基本的正则表达式:
'c' = {"c"}
ɛ = {""}
复合正则表达式:
并(Union)
链接(Concatenation)
迭代(Iteration)

某一个字母表 \(\Sigma\) 上的正则表达式就是最小正则表达式的集合包含:
R = ɛ
| 'c' c ∈ \(\Sigma\)
| R + R
| RR
| R*
上面这种用于描述正则表达式的方式称为 文法(Grammar)
比如对于字母表 \(\Sigma = \{0, 1\}\),可以写出其上的正则表达式包含:
1*
(1 + 0)1
0 + 1
(0 + 1)*(由于这个正则表达式包含了所有字母表能组成的字符串,所以也称其为 \(\Sigma^*\))
同一个正则语言表达方法也不唯一,比如 (1 + 0)1 也可以写作 11 + 01
-Week 2 03-04-formal-languages
语义函数 \(L\) 将 语法 映射到 语义 $$ L(e) = M $$ \(L: Expressions \to Sets\ of\ strings\)

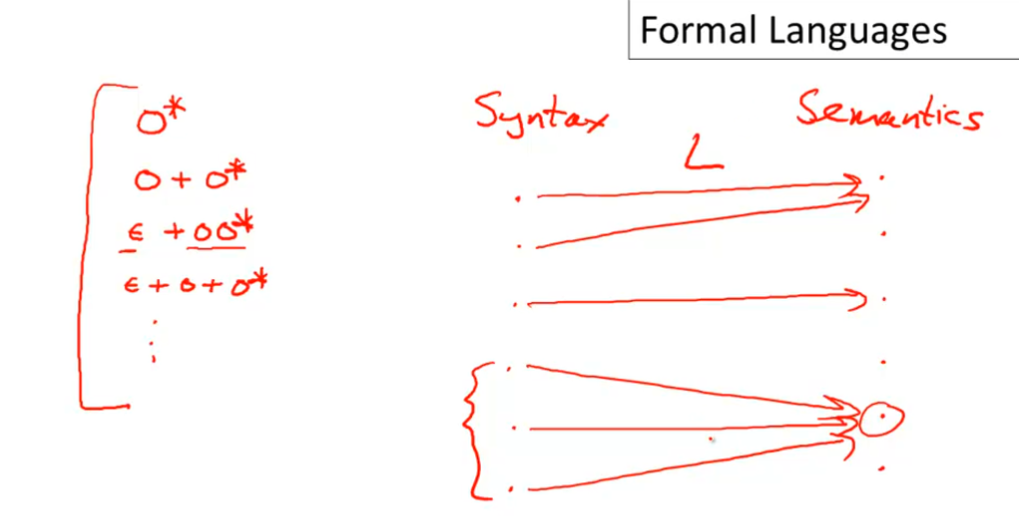
-形式语言、自动机与正则表达式
啃啃铎铎的书
一、语言
字母表(alphabet)指的是一个有限的非空符号集 \(\Sigma\),其中元素称为 字母。
由字母表 \(\Sigma\) 生成的有限长度序列全体写作 \(\Sigma^*\),其中元素称为 \(\Sigma\) 上的 词 或 串,其中的空序列称为 空串(empty string) 或 零串(null string),习惯上用 \(\lambda\) 或 \(\varepsilon\) 表示,并使用 \(\Lambda\) 表示集合 \(\{\lambda\}\)。
-Week 1 02-03-cool-example-iii-final-correction
这一节主要是用 cool 实现了个列表类型,用于理解 cool 和类相关的东西,懒得细看,所以先撇这儿。
(下面这个不是视频里写的代码,是我直接从 example 目录扣出来的
-Week 2 03-01-lexical-analysis
词法分析(Lexical Analysis)
首先以一个小的代码片段为例:
词法分析的目的就是划分出 词素(Lexemes),对于人来说很容易能做到(因为有各种视觉上的线索,如分隔符标点符号、换行),但是对于词法分析器来说,这只是一串字符串:
| Text Only | |
|---|---|
首先词法分析器会遍历这个字符串并且在该分割的地方进行分割,得到词法单元,但是更重要的是它要识别出 词法单元的类型(Token Class)。
比如对于人类语言来说:就是区分出名词、动词、形容词等。
而对于编程语言来说:就是区分出关键字、标识符、左右括号、各种常亮等。