所有权 1 所有者、移动、克隆
一、栈和堆
在程序运行时可供使用的内存包含 栈区 和 堆区,对应着两种不同的数据结构 栈 和 堆,他们的特性不同,存储的数据也不同。
栈区 中存储的数据必须是 占用已知且固定的大小 的,而 堆区 中存储的数据是 编译时大小未知或可能变化 的。
在程序运行时可供使用的内存包含 栈区 和 堆区,对应着两种不同的数据结构 栈 和 堆,他们的特性不同,存储的数据也不同。
栈区 中存储的数据必须是 占用已知且固定的大小 的,而 堆区 中存储的数据是 编译时大小未知或可能变化 的。
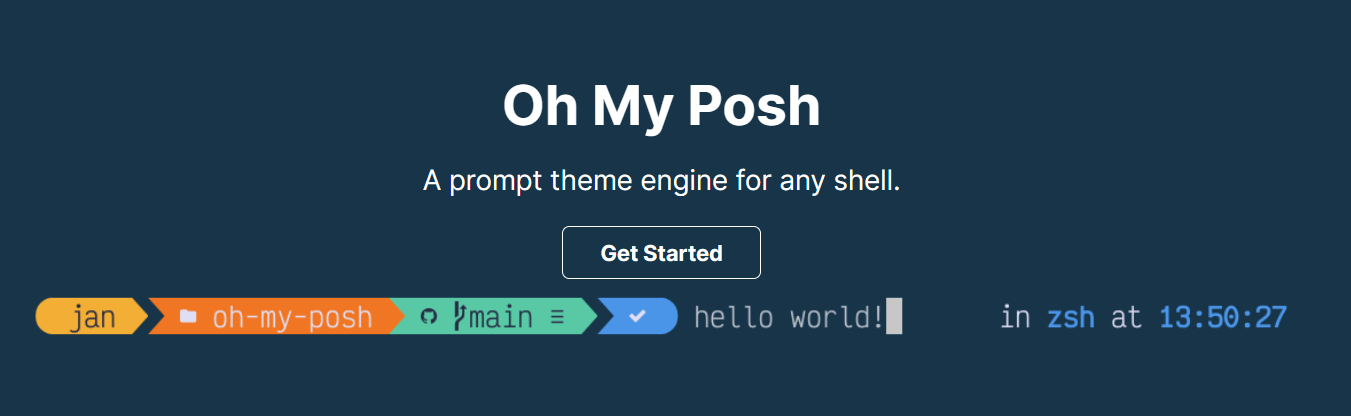
「可定制性最强、延迟最低的跨平台 / Shell 提示符渲染器」
懒得写介绍了,简单来说,就是把你的命令行 / shell 变好看。
可以通过 Scoop / Winget 来安装,当然也可以通过一行 Powershell 命令下载官方的安装脚本并执行手动安装,这里选择使用 Scoop 安装:
| PowerShell | |
|---|---|
上面的命令会安装两样东西:
oh-my-posh.exe 可执行文件themes 最新的 Oh My Posh 主题可以在 POSH_THEMES_PATH 环境变量对应的文件夹中找到主题,
Nerd Fonts 官网:Nerd Fonts - Iconic font aggregator, glyphs/icons collection, & fonts patcher

Oh My Posh 显示图标需要 Nerd Fonts 字体,所以这一步我们需要安装一款 Nerd Fonts 字体并设置终端使用它。Nerd Fonts 字体并不是一个具体的字体,而是一系列字体。其中的每一个字体都可以看作是 某一个流行字体 + 一系列图标字体(如上图)。同时,Nerd Fonts 中大部分经过修改后的字体会拥有一个新的名字,但是和原本的名字很像,比如很知名的 SourceCodePro,在 Nerd Fonts 中经过“改造后”就被称为 SauceCodePro Nerd Font,很有趣。
你可以选择手动从官网下载并安装,不过现在 Oh My Posh 命令可以直接安装:
| Text Only | |
|---|---|
这里
sudo是通过 scoop 安装的,用处就是以管理员权限执行该命令。如果没有sudo就在有管理员权限的终端下执行命令。当然也可以制动
--user来不用管理员权限,仅安装到当前用户下,不过对于一些应用可能会有一些副作用,字体还是安装到整个系统而非某个用户比较好。
不过我这里依旧选择使用 scoop,主要是方便更新之类的:
| Text Only | |
|---|---|
然后在 Windows Terminal 中设置使用它:

针对不同的 shell 有不同的方式,这里只写 powershell 的方式,详情参考官方文档:Change your prompt | Oh My Posh 如果不知道使用的是哪个 shell 可以运行:
PowerShell
编辑 PowerShell 的 profile 脚本(你可以使用任意的编辑器,这里我就用 neovim 了):
| PowerShell | |
|---|---|
添加下面一行:
| PowerShell | |
|---|---|
然后通过下面的命令来重新加载 profile:
| PowerShell | |
|---|---|
可以看到效果已经生效了:

如果不指定配置,Oh My Posh 会使用其默认配置,若想指定配置则需要修改 profile 中的初始化命令添加 --config 选项:
可以添加两种 --config 选项:
| PowerShell | |
|---|---|
| PowerShell | |
|---|---|
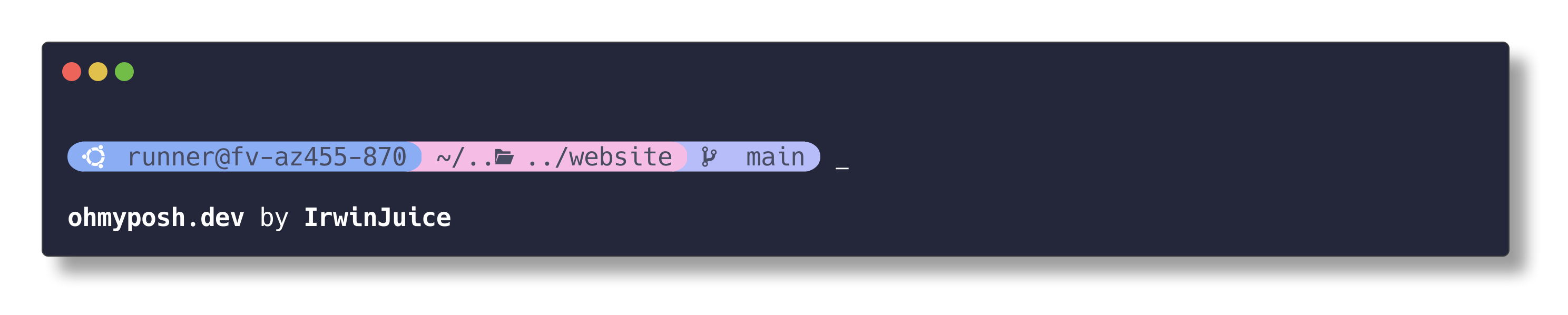
我们首先先使用一些 Oh My Posh 中的 themes 中带有的配置:
使用 Get-PoshThemes 可以在 powershell 中渲染出每一个主题的样子。
比如我们切换使用 catppuccin 主题:
| PowerShell | |
|---|---|
有关更详细的自定义,参阅文档:General | Oh My Posh。
斐波那契数列的定义如下:
根据这个我们不难写出 递归 方式求解斐波那契数列的代码:
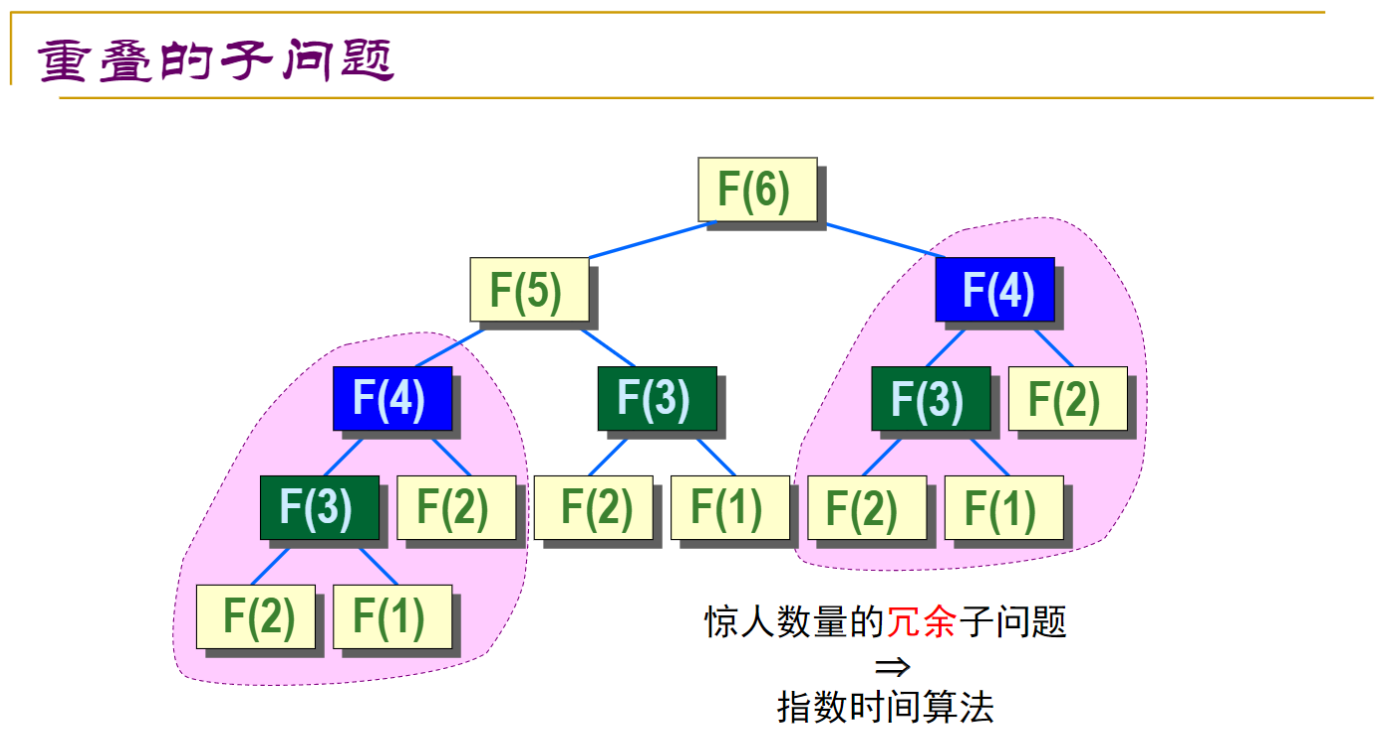
然而通过简单的实验,可以发现这种方式效率极低:

其时间复杂度 \(T(n) = T(n-1) + T(n-2)\),可以推导出为 \(O(2^n)\) 的。造成如此的效率低下的原因就是 进行了太多次重复的运算。如果我们将递归求解的过程化成一棵树,我们可以发现其中有太多太多重复的部分:
另一种方法是以递推的方式进行求解:
如此其时间复杂度是线性的,能够解决上述递归方式重复计算子问题导致效率低下的问题。
另外还有一种方式,通过对递归方式加一点修改也可以解决这个问题。那就是 记忆化搜索,将搜索过程中的结果保存下来,并在之后的搜索过程中加以利用:
目标:给定面值分别为1元、5元、10元的硬币(每种都有足够多枚),请设计一个算法,可以使用最少数量的硬币向客 户支付给定金额。
如果还有面值为7元的硬币,那么贪婪算法可能就无法得到最优解了
对于给定的硬币组,如何找到凑成给定金额 n 的最小硬币数?
每一次选择必定要从 1、5、7、10 中选一个,于是可以据此将选择分为四种情形:
而为了保证最终的金额最小,上面的 n-1、n-5、n-7、n-10 要以最优方式拼凑出来。
分别计算以上情形后选择一个最佳方案即可。
但是。。这不就是暴力搜索么。
假如将问题一般化,对于目标数值 \(n\) 和 \(m\) 种面值分别为 \(d_1, d_2, \cdots, d_m\) 的硬币,当 \(n\) 和 \(m\) 更时,这种算法的效率将极其低下,原因依旧是太多的 重复计算。
我们能不能依旧按照 一 中的思路,使用递推来降低时间复杂度呢?
可以发现,我们要想求解 \(n\) 元的问题,就要先求解 \(n-d_1, n-d_2, \cdots, n-d_m\) 元的问题,以此类推直到求解 \(d_1\) 元的问题,此时只有一个选项,就是选它。
那么我们可以换一种思路,从 \(d_1\) 元的问题开始,利用已知的信息逐步推演得到 \(d_1 + d_1, d_1 + d_2, \cdots d_1 + d_m\) 元的问题的答案,以此类推利用已知的信息推演出所有最优情况,最终确定 \(n\) 元的问题的答案:
咕
首先先回顾一下矩阵的乘法:
可以写作:
很容易可以写出其伪代码:
当对多个矩阵进行链式乘积时,以何种顺序进行运算就成为了一个影响性能的至关重要的问题。
例如我们有这样三个矩阵:\(A_{10 \times 100}, B_{100 \times 5}, C_{5 \times 50}\)
两种截然不同的方式将导致完全不同的元素乘法次数:
\((AB)C = D_{10 \times 5} \cdot C_{5 \times 50}\):共 \(10 \cdot 100 \cdot 5 + 10 \cdot 5 \cdot 50 = 7,500\) 次元素乘法
\(A(BC) = A_{10 \times 100} \cdot E_{100 \times 50}\):共 \(10 \cdot 100 \cdot 50 + 100 \cdot 5 \cdot 50 = 75,000\) 次元素乘法
矩阵链乘积问题如下:
对于给定矩阵序列 \(A_1, A_2, \cdots, A_n\),其中 \(A_i\) 的阶数为 \(P_{i-1} \times P_{i}\),试确定矩阵相乘的次序使得元素乘法总次数最少。
每一次乘法相当于将整个矩阵序列划分为两部分,将相邻处的两个矩阵“合并”: $$ A_{i..j} = A_{i..k} \times A_{k+1..j} $$ 若令 \(F_{i,j}\) 表示 \(A_{i..j}\) 中元素乘法的次数,那么可以知道对于任意的 \(k\) 有: $$ F_{i,j} = F_{i,k} + P_{i-1} \cdot P_{k} \cdot P_{j} + F_{k+1,j} $$ 那么对于某一个 \(i, j\),只要得出对于任意的 \(i \leq k < j\) 的元素乘法次数,再求最小值即可。同时也要使 $F_{i, k} $ 和 \(F_{k+1, j}\) 最小。
现在我们直接列出其递推式:
伪代码如下:
Trigger 其实就是一个数据库在特定操作后自动执行的一种函数。
它可以被连接到表和视图。
在表上,触发器 可以被定义为在任何 INSERT,UPDATE,DELETE 操作 之前 或 之后 执行,且可以分为 对每条语句执行一次 还是 对每一个被修改的行执行一次。
对于 UPDATE 操作,还可以指定 特定的行被更新后 执行。
在 视图 上,触发器 可以被定义为 代替 任何 INSERT, UPDATE, DELETE 操作执行。
触发器可以分为 语句级 的和 行级 的:
在 BEFORE 触发器中无法访问语句产生的改动
在 AFTER 触发器中可以访问语句产生的所有改动
BEFORE 触发器无法访问语句所产生的改动(因为语句还未执行),而 AFTER 触发器可以访问语句所产生的所有改动。
| PostgreSQL SQL Dialect | |
|---|---|
其中 event 可以是 INSERT,UPDATE [ OF /*column_name*/ [, ...] ],DELETE。
data change trigger 是一个满足以下条件的函数:
无参数
返回类型为 trigger
在这样的触发器中有一些特殊的变量可以访问:
NEW类型为 RECORD,在 行级 触发器中。
其值为 INSERT/UPDATE 操作的 新 的行。
OLD类型为 RECORD,在 行级 触发器中。
其值为 INSERT/UPDATE 操作的 旧 的行。
假设你了解基本的 Python 语言知识,并理解 Python 包的管理方式。
以下内容需要进行了解:
Jupyter Notebook 顾名思义,是一个笔记应用,它编辑的笔记后缀为 .ipynb,笔记的内容以块为单位组织,块分为 Markdown 内容块和 Python 代码块(其实也支持一些其他数据科学常用的语言),其中的每一个块都可以执行,Markdown 内容快执行的效果即进行渲染,代码块执行的效果即将运行的输出以及最后一条语句的值显示出来。
但说他是个应用,其实不完全是,因为它其实是一个 Web 服务,分为前后端。前端网页负责提供笔记的界面并与后端沟通,而后端 Jupyter 内核负责与 Python 解析器交流。
可以达到下面的效果:
Anaconda 是一个 Python 发行版本,其中包含 Python 本体、conda 以及 180+ 个和数据科学有关的 Python 包。他还有另一个精简版本叫做 Miniconda,可以理解为不带有那 180+ 个 Python 包,使得用户可以选择只安装自己需要的包,减小了占用的空间大小。
pip 是 python 用于管理依赖的工具,比如我要安装一个名为 matplotlib 的包,我只需执行 pip install matplotlib。
venv 和 virtual env 都是用于创建独立的 Python 环境的工具,前者是 Python3 标准库自带的,而后者是一个单独的 Python 包。有时我们写的不同项目会用到不同版本的 Python,甚至会用到不同版本的同一个包,此时独立的环境就极为重要。
conda 是一个用于管理依赖和环境的工具,可以理解为对 pip 和 venv 的组合,使用起来更加便捷。
前往 Jetbrains 官网:JetBrains: 软件开发者和团队的必备工具

安装完成后打开会有这样一个界面:

这里要求你对默认的环境进行配置,其中:
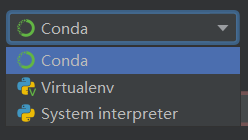
可以选择去官网下载安装,但是这里我选择使用 Scoop 安装。
有关 Scoop 见 aoike - 告别繁琐安装界面,使用Scoop管理Windows软件 (azurice.github.io)

| Text Only | |
|---|---|
然后在刚才 DataSpell 的 Conda Executable 中选择这个文件:
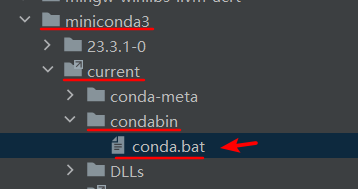
Launch DataSpell!
进去后,就是经典的 Jetbrains IDE 的布局。
但是它并不是按照 项目(Project)来组织的而是按照 工作区(Workspace)来组织的:
每一个工作区中可以包含多个目录,目录可以通过按钮来进行添加。也就是说它是连接到各个位置的目录,而非将一切放到一个目录下。
比如我这里添加了一个路径为 F:\Dev\AI 的目录:
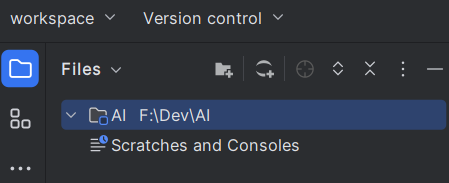
你可以为每一个目录选择不同的解释器:

不过目前我们不用管他。
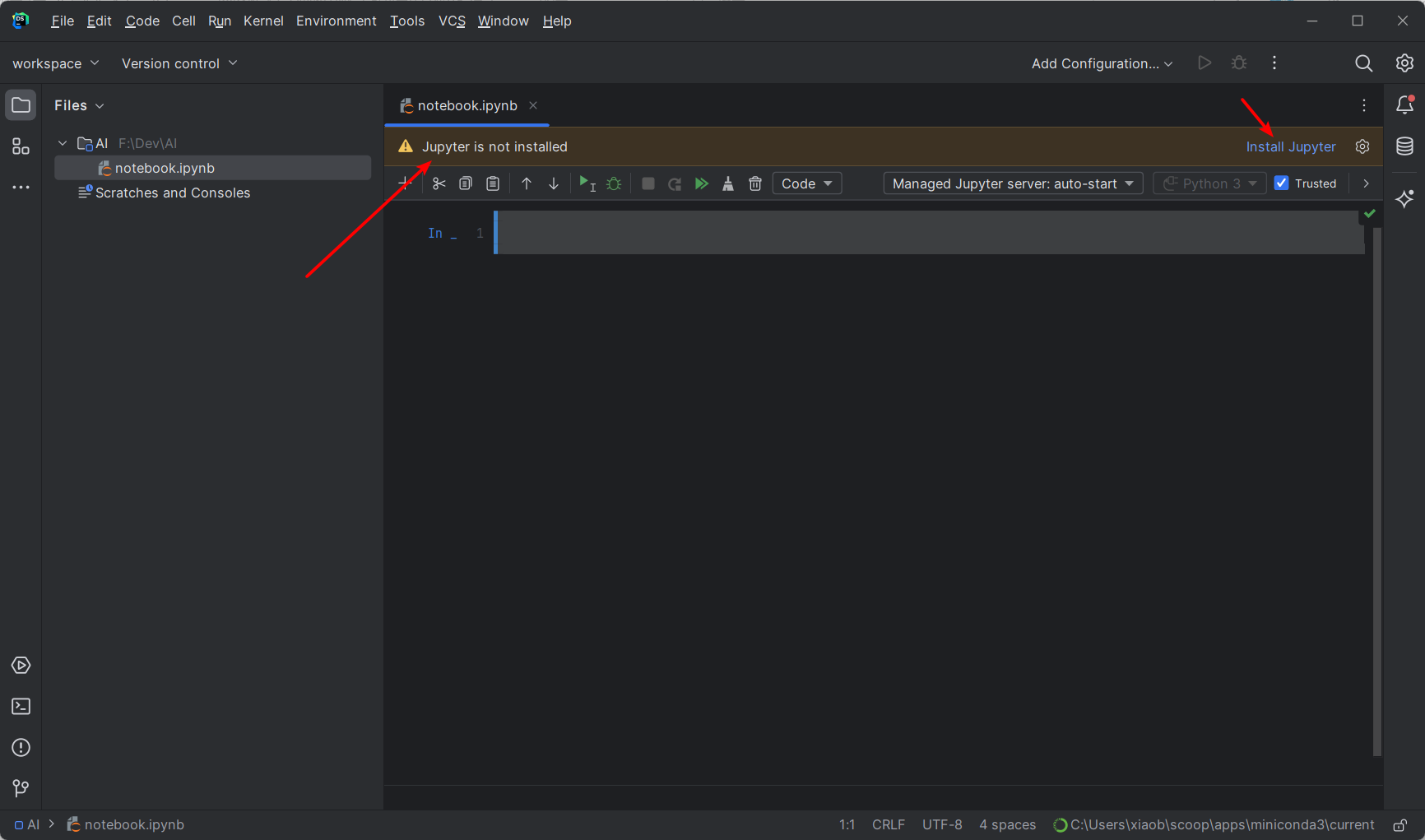
创建一个 Jupyter Notebook 文件:

创建完毕后打开,它会提示你没有安装 Jupyter,点击安装,安装完成后等待 Updating skeletons 完成,即可:

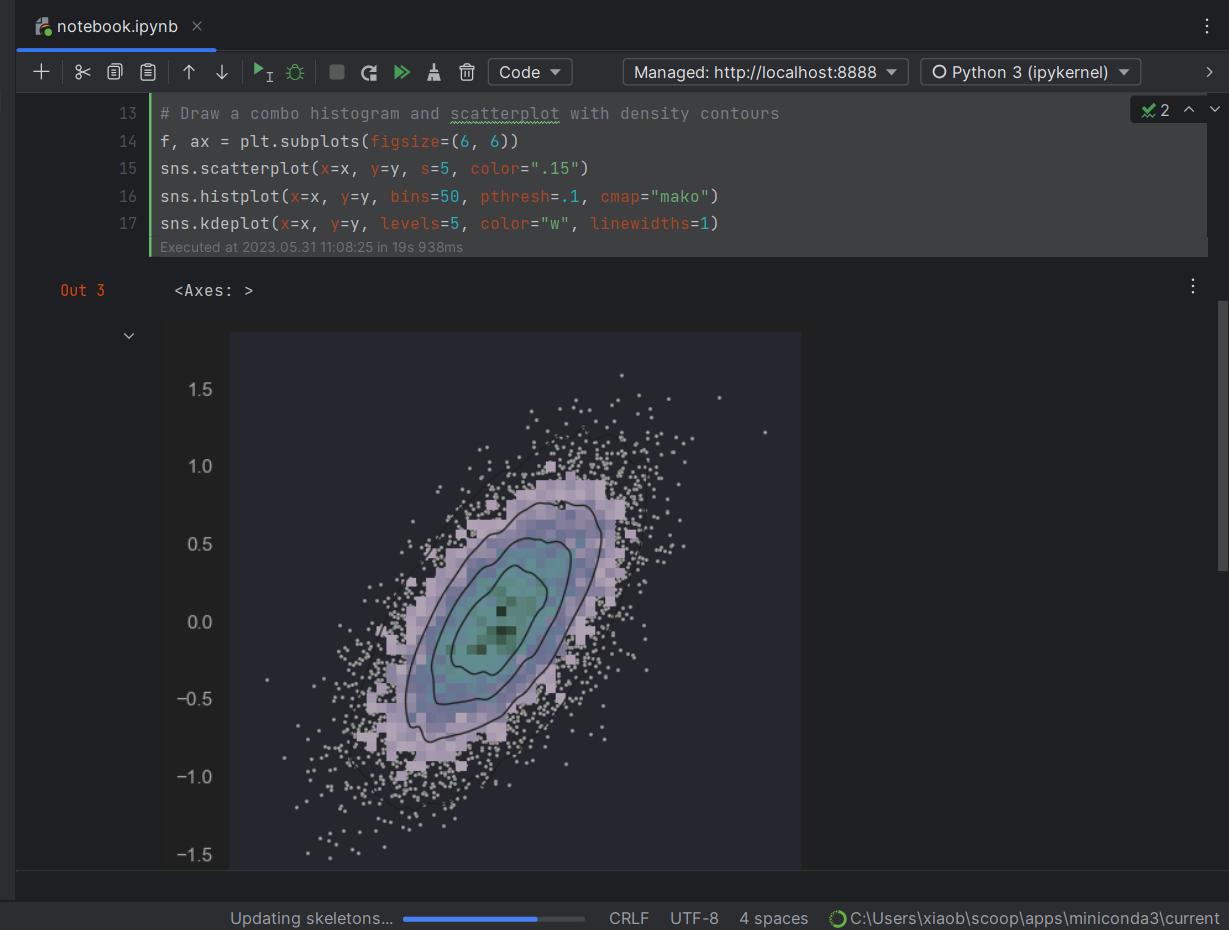
至于为什么用 DataSpell 而不直接用 Jupyter 呢?因为 DataSpell 有代码补全:

这些个按钮自己理解一下,这个代码块的运行效果如下:

提示没有安装库可直接将鼠标移到红线上后点击浮动框中的 Install,或者手动执行:
| Text Only | |
|---|---|
要求:参考三个选题(手写体数字识别、人脸识别、猫狗识别),可以结合大创的项目。不可以选择百度 AIStudio 上原封不动的项目,必须有所修改,或者修改模型结构,或者修改数据集。否则,20 分的项目,最多得 10 分。
手写体数字识别属于典型的图像多分类问题
实践平台:百度AI实训平台-AI Studio
实践流程:
准备数据
配置网络
实验要求:
按实践流程调通程序
采用MNIST数据集,原数据集中只有黑底白字,在原数据集中增加白底黑字的数字图像,即:使得系统也能识别白底黑字的数字图像。
撰写实验报告
将调通的程序发布到百度AI实训平台-AI Studio上,将实验报告提交到指定的助教邮箱。
实验最终准确率(占2分):按准确率高低的排序给分。
实验尝试的模型(占3分):使用2个及以上经典卷积网络(如VGG等)的,得3分,使用1个经典CNN的得2分,未使用经典CNN的得1分。
实验调参(占2分):对学习率、优化器、模型的深度和宽度(隐层中神经元的数目)、激活函数等,进行过10次及以上尝试者,得2分;只进行少于10次尝试者得1—1.5分。
实验数据分析(占3分):以图表的形式展示实验结果,在此基础上进行深入讨论者,得3分;讨论内容肤浅者,得1--2分。
| 总分 | 最好的 accuracy(或 Precision 和 Recall) | 演示功能正确 | 超时 | 阐述清晰 | 回答问题正确 |
|---|---|---|---|---|---|
| 10 | 2 | 3 | 2 | 2 | 1 |
其中,超时不包括提问环节,超时和最好的 accuracy(或 Precision 和 Recall)全组统一。
每组答辩时长 15 分钟,不需要制作 PPT,每人陈述 3 分钟,即自述 12 分钟。组员分工介绍以下内容:
项目思路
数据集规模,训练集、(验证集)、测试集的样本分配
模型的网络结构:几层卷积层、几个卷积、卷积大小、激活函数、损失函数、池化层、全连接层、输出层几个神经元
展示运行结果
回答问题 3 分钟(覆盖课堂讲授的理论和实践内容),每人回答一个问题。
每组组员的得分不同,取决于个人在“阐述清晰”、“回答问题正确”、“演示功能正确”环节的表现。
必须弄清楚 CNN 术语含义,尤其在分组答辩时,要用对术语,否则我的问题,你可能答不到点子上,也会浪费时间。
若连老师所提的问题都听不懂,或弄错术语的含义,直接扣分。
通过 Python 获取网页数据的方法一般分为两大类:
基于 HTML 正则匹配
基于 API 请求
前者很简单,其实就是字符串匹配,不过缺点就是较为繁琐复杂;后者也很简单,就是伪装浏览器发请求即可。
下面简单讲一下。
假设你已经安装好 Python。
如何安装可以百度。不过我这里推荐一个工具,叫做 Scoop。它是一个 Windows 下的包管理器,可以在终端通过简单的一行命令完成一些软件包的安装、升级、卸载等,而且可以免掉图形化的安装界面,不必下一步下一步的点,此外也用了特殊的方法来管理环境变量,不必再配置为环境变量发愁。具体可以见 aoike - 告别繁琐安装界面,使用Scoop管理Windows软件 (azurice.github.io)。
众所周知,每一个网页都是一个 .html 文件,一个标准的 HTML 文档的结构大概长这样:
其中尖括号扩起来的一个个东西叫做 标签,标签成对出现,如 <sometag></sometag>,当然如果某些标签中不包含任何内容,也会写作 <sometag />。
标签可以携带一些属性,比如 <script type="text/javascript"></script>,它有一个值为 "text/javascript" 的 type 属性。
介绍一个重要的网站,上面包含一切 web 技术的文档:MDN Web Docs (mozilla.org)
在一般的浏览器中按 F12 选择 元素 一栏,便可以看到网页整个的 HTML 代码。
也可以通过在目标元素处右键 -> 检查,来快速定位到其对应的 HTML 代码位置。

比如对于这个页面:https://space.bilibili.com/46452693

我想爬取他的关注、粉丝、获赞等信息。
通过 F12 我们发现,这部分对应的代码是这样的:
这一部分内容位于一个 class 为 n-statistics 的 div 块中,也就是说只要我们在整篇 html 中找到这一部分,就可以从中分离出我们想要的数据。
但是怎么找?简单的字符串匹配么?
正则表达式可以用于描述一组字符串。
比如 <div class="n-statistics">.*</div> 即可匹配上面的内容。
再进一步,<p id="n-.*>(.*)</p> 即可匹配出五个数据。
详细内容可以再查一查。
可以看看这个:Python 正则表达式 | 菜鸟教程 (runoob.com)
简单搓了段码:
但是,直接这样运行并不能得到想要的结果,如果将 page 打印一下会发现只有如下的内容:
首先,大多数网站都有反爬机制,一种常见的反爬机制就是通过请求的 headers 中的 User-Agent 来判断是否是一个真正的浏览器发送的请求。那么绕过这个机制也很简单,我们将一个真正的浏览器的 headers 中的 User-Agent 设置给 python:
现在,确实发现获取到的内容发现了改变,但是依旧不是一个完整的网页:
这就是另一种反爬机制,一些数据是动态加载或延迟加载的,并不会直接出现在网页上,要想获取完全加载完毕的网页,可能需要借助 Selenium 库(这个一会会提到)。
不过这里为了演示,就直接手动将页面的部分内容赋给了 page:
现在就可以得到输出:
| Text Only | |
|---|---|
刚才提到有很多反爬机制会使得直接对网页的获取并不能得到我们实际在浏览器看到的网页,这时候就需要借助 Selenium 库。
Selenium 是一个浏览器自动化库,可以通过浏览器对网页各个元素进行访问以及操作。具体可以查一查或啃一啃官方文档。
这里给一个我爬取文泉书局电子书的例子:
https://wqbook.wqxuetang.com/read/pdf?bid=2135236
上面这个网页中就包含我想要爬取的 pdf,这个网站做了很多层反爬,一年前我爬大学物理教材的时候它的反爬还没这么厉害(),下面简单讲一下。
首先,第一层反爬,在网页按 F12 无法调出开发者工具。
这是因为网页代码屏蔽了相关的按键。
解决办法:先打开其他网页,调出开发者工具,再修改地址栏回到这个网页即可。
然后我们可以发现,pdf的内容都被显示在 <img> 标签中,而且还是 base64 编码的,这意味着我们直接获取字符串进行解码即可得到图片数据:

但是。。等一下。这并不是真实的页面,这是一张清晰度极低的预览图,而页面真正的图片被纵向切分成了 6 份:

这就意味着,我们需要分辨出这六分的顺序,分别解码对应的图片,再进行拼接才能得到一张完整的页面。
这就是第二层反爬。
第三层反爬,很显然,不用试,这里的数据也是动态加载的,无法直接通过 get 网页地址来获取完整的网页,这就需要我们使用 Selenium 操纵浏览器模拟人的行为一页一页翻页。
第四层,这个输入页码的地方。

它只有在被点击后才会显示出要输入页码的元素:

而且还被折叠在 div 块中,想要将其展开看一看里面的标签长什么样又会由于这个点击使得这个输入页码的地方隐藏。
不过,还是被我爬了(
码如下
| Python | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | |
因此这种方式一般为下策,十分繁琐且复杂。
还是 B 站的那几个数据,既然它是动态加载的那么它一定会向服务端发送网络请求来获取数据,只要我模拟浏览器,向相同的 URL,用相同的参数发送请求,不久也可以得到相同的数据了么。
在网络这一栏中我们可以寻找一下数据的请求:

于是我们很快的就找到了(这里也是有一些技巧,比如一般是属于 Fetch/XHR 类型的,选上它可以排除掉大部分请求):

可以发现是这样的一个请求:

于是事情变得简单了起来:
得到:
| Text Only | |
|---|---|
但是这里只有关注数和粉丝数,这是因为其他在另一个接口中:

但是如果我们直接请求:
得到的会是空数据:
| Text Only | |
|---|---|
这是没有登陆导致的,很多接口会设计为对登录与否返回不同的数据,或者只有登录才能访问。
可以通过在浏览器登陆后将浏览器的 cookie 设置给 python 来做到伪装登录:

现在就好了:
| Text Only | |
|---|---|
大概就是这两大类方法,写得比较简陋,可以简单看看。
如果有问题可以随时讨论。
主要两种方法:
-+ 选项(或者添加 %option c++),这样就会生成 lex.yy.cc 而非 lex.yy.c使用第二种方法:
在 .l 文件中的 defination 部分添加
| Text Only | |
|---|---|
即可。
生成的 lex.yy.cc 文件中会引入一个 FlexLexer.h 头文件,其中定义了一个 FlexLexer 类,这是一个抽象的基类,定义了一般的扫描器类接口,在该类中提供了以下成员函数:
